European Metadata Header
From XBRLWiki
CEN Workshop Agreement
Status: Working Group Working Draft
CEN WS XBRL Expert: Javi Mora (XBRL Spain)
Editing rules
Editorial comments should be highlighted as follows: A comment
Text or rules in discussion (white): Some text
Text or rules already aligned (green): Some text
Text or rules to be deleted (red): Some text
Text to be delivered (blue): Some text
Foreword This document is a working document. This document is a draft of the upcoming CWA2 header specification.
Scope
The basic scope of this sub-group is to provide the specifications of a standard metadata container to enable XBRL sourcing, with in addition necessary compliance tools to enable all stakeholders to test and ensure full adherence to the technical standards.
Metadata such as sender of the document, contact details, date and time of submission, version etc. are not included in the taxonomies, because they don’t really belong to the data model. On the other hand, and often for legal reasons, these data are required by national regulators. As a consequence, a variety of national protocols has been engineered, which complicates the life of cross-border institutions, but also prohibit the possibility to create a harmonized European collection system. Metadata are needed as well for financial reporting as for company legal and economic data.
This document of the CWA will only describe the header part of the metadata container and provide mechanisms for transmitting the administrative data. The approach chosen is the definition of an XML schema with all necessary data; it includes the “Core Business Vocabulary 1.00” as defined by the European Union in May 2012. The present document explains the XML schema developed and gives precisions on the use of all fields.
Normative references
The following referenced documents are indispensable for the application of this document. For dated references, only the edition cited applies. For undated references, the latest edition of the referenced document (including any amendments) applies.
W3C XML Schema Definition Language (XSD) 1.1
XBRL International (XII), Extensible Business Reporting Language (XBRL) 2.1, Recommendation – 2003-12- 31
European Commission, ISA e-Government Core Vocabularies v2.0, February 2012.
European Commission, ISA Core Business Vocabulary v1.00, May 2012.
Terms and definitions
For the purposes of this document, the terms and definitions given in next sections and the following apply.
Container
In software development terminology, the word container is used to describe any component that can contain other components inside itself.
Content-related validations
validations applied to the content of a specific file or document.
Core concept
is a simplified data model that captures the minimal, global characteristics/attributes of an entity in a generic, country- and domain-neutral fashion. It can be represented as ‘Core Vocabulary’ using different formalisms, for example XML (eXtensible Markup Language).
Core vocabulary
is a simplified, reusable, and extensible data model that captures the fundamental characteristics of an entity in a context-neutral fashion [EGOV-CV]. Well known examples of existing Core Vocabularies include the Dublin Core Metadata Set [DC]. Such Core Vocabularies are the starting point for agreeing on new semantic interoperability assets and defining mappings between existing assets. Semantic interoperability assets that map to or extend such Core Vocabularies are the minimum required to guarantee a level of cross-domain and cross-border interoperability that can be attained by public administrations.
e-Government
is about using the tools and systems made possible by information and communication technologies (ICTs) to provide better public services to citizens and businesses
European Interoperability Strategy (EIS)
The European Interoperability Strategy (EIS) provides the basis for defining the organisational, financial and operational framework (including governance) needed to ensure on-going support for cross-border and crosssector interoperability, as well as the exchange of information among European public administrations.
European public service (EPS)
A cross-border public sector service supplied by public administrations, either to one another or to European businesses and citizens.
Full container
A container submitted to an authority containing XBRL instances containing a full set of reporting data set as defined by the authority; it will not only respect all structural validations, but also all content-related XBRL validations.
Header
In a computer file, a header may be a field that precedes the main file content and describes the length of the content or other characteristics of the file.
In a network transmission unit, a header precedes the data or control signals and describes something about the file or transmission unit, such as its length and whether there are other files or transmission units logically or physically associated with this one.
Information and Communication Technology (ICT)
Technology, e.g. electronic computers, computer software and communications technology, used to convert, store, protect, process, transmit and retrieve information.
initial container
A container submitted to an authority containing an initial set of XBRL instances for a certain period, entity and reporting type; an initial container will be marked as such in the header XML instance.
interoperability
Within the context of European public service delivery, it is the ability of disparate and diverse organisations to interact towards mutually beneficial and agreed common goals, involving the sharing of information and knowledge between the organisations, through the business processes they support, by means of the exchange of data between their respective ICT systems.
partial container
A container submitted to an authority containing XBRL instances covering a subset of the reporting data set defined by the authority; it will respect all structural validations, but not necessarily all content-related XBRL validations (some of these validations will simply fail because of the lack of some data in the partial container).
semantic interoperability
It is the ability of information and communication technology (ICT) systems and the business processes they support to exchange data and to enable the sharing of information and knowledge: Semantic Interoperability enables systems to combine received information with other information resources and to process it in a meaningful manner (European Interoperability Framework 2.0). It aims at the mental representations that human beings have of the meaning of any given data.
Semantic Interoperability Centre Europe (SEMIC.EU)
SEMIC.EU (Semantic Interoperability Centre Europe) is a collaborative platform and service offered by the European Commission to support the sharing of interoperability assets to be used in public administrations and eGovernment (http://www.semic.eu).
SGML
Short for Standard Generalized Markup Language, a system for organizing and tagging elements of a document. SGML was developed and standardized by the International Organization for Standards (ISO) in 1986. SGML itself does not specify any particular formatting; rather, it specifies the rules for tagging elements. These tags can then be interpreted to format elements in different ways.
SGML is used widely to manage large documents that are subject to frequent revisions and need to be printed in different formats. Because it is a large and complex system, it is not yet widely used on personal computers. However, the growth of Internet, and especially the World Wide Web, is creating renewed interest in SGML because the World Wide Web uses HTML, which is one way of defining and interpreting tags according to SGML rules.
standard
As defined in European legislation (Article 1, paragraph 6, of Directive 98/34/EC), a standard is a technical specification approved by a recognised standardisation body for repeated or continuous application, with which compliance is not compulsory and which is one of the following:
- international standard: a standard adopted by an international standardisation organisation and made available to the public,
- European standard: a standard adopted by a European standardisation body and made available to the public,
- national standard: a standard adopted by a national standardisation body and made available to the public.
standards developing organisation
A chartered organisation tasked with producing standards and specifications, according to specific, strictly defined requirements, procedures and rules. Standards developing organisations include: recognised standardisation bodies such as international standardisation committees such as the International Organisation for Standardisation (ISO), the three European Standard Organisations: the European Committee for Standardisation (CEN), the European Committee for Electrotechnical Standardisation (CENELEC) or the European Telecommunications Standards Institute (ETSI); for a and consortia initiatives for standardisation such as the Organisation for the Advancement of Structured Information Standards (OASIS), the World Wide Web Consortium (W3C) or the Internet Engineering Task Force (IETF).
structural validations
XML schema validations and structural XBRL validations (XBRL 2.1, Dimensions 1.0 etc. or higher)
tag
A command inserted in a document that specifies how the document, or a portion of the document, should be formatted, or gives information about the content of it. Tags are used by all format specifications that store documents as text files. This includes SGML and XML.
taxonomy
A taxonomy represents a classification of the standardised terminology for all terms used within a knowledge domain. In a taxonomy, all elements are grouped and categorised in a strict hierarchical way, and are usually represented by a tree structure. In a taxonomy, the individual elements are required to reside in the same semantic scope, so all elements are semantically related with one another to one degree or another.
update container
A container submitted to an authority containing XBRL instances covering a correction of the latest initial container sent; it will be marked as such in the header XML instance and is usually a partial container.
validations
Set of conditions that verify that something is correct or conforms to a certain standard. In data collection or data entry, it is the process of ensuring that the data that are entered fall within the accepted boundaries of the application/process collecting the data.
vocabulary
A vocabulary is a set of terms (words or phrases) that describe information in a particular domain.
workflow
The organisation of a process into a sequence of tasks that are performed by duly designated sets of actors fulfilling given roles in order to complete the process.
XBRL
Short for eXtensible Business Reporting Language, an XML-based specification for publishing the financial information of an enterprise. The standardization of the specification makes it easier for public and private companies to share information with each other and with industry analysts across all software formats and technologies, including the Internet. XBRL uses XML data tags based on standardized accounting industry definitions to describe financial information for public and private companies and other organizations. The financial information includes such data as annual and quarterly reports, SEC filings, general ledger information, net revenue and accountancy schedules.
XML
Short for eXtensible Markup Language, a specification developed by the W3C. XML is a pared-down version of SGML, designed especially for Web documents. It allows designers to create their own customized tags, enabling the definition, transmission, validation, and interpretation of data between applications and between organizations.
XML Schema or XSD
XSD is a short for XML Schema Definition, a way to describe and validate data in an XML environment. (A schema is a model for describing the structure of information.) XSD is a recommendation of the W3C, and is defined in the W3C's XML Schema Working Group Working Draft published on May 6, 1999. TC XBRL WI XBRL002:2012 (E)
XML Header
The header is the way of transmitting the usual metadata that determine the context of a reporting instance (the sender of the document, type of reporting, contact details, date and time of submission, etc.). The header is the only file with a naming convention: “header.xml” and it is located on top-level of the compression package.
In our case, the header will list XBRL instances contained in the container, and these instances should always have extension “.xbrl”. The use of folders in the path to the instance is optional; in case they are used, all references (in header to XBRL instances; in XBRL instances to taxonomy files) must respect them.
The header file will be a separate XML instance, and a package of multiple XBRL instance documents may have just one XML header file. The header has no integration with XBRL (no extension or integration with any XBRL taxonomy) and makes direct import of the core business vocabulary. The different parts of the header file are defined as follow:
Sender
The sender is the entity that owns the authorship of the document at different levels:
- Technical Sender: Technical responsible for the submission process, including transport to the authority, encryption, digital signature etc.
- Functional Sender: Responsible for the gathering of the data and the report generation
- Declarer: Entity supervised by the authority which the financial figures are related to (it may be functional and technical sender at the same time or outsource those functions).
After identifying the type of the sender, a legal identifier as well as adequate contact persons should be given and formally identified for the entity. The definitions of all the concepts included in this first part of the header are detailed below, and most of them are in common with the Core Business Vocabulary (see Core Vocabularies Specification).
Legal Identifier (see Core Vocabularies Specification - section 3.1.12 identifier)
For many systems, the identifier is the key piece of information about an individual and therefore an important part of the core business vocabulary. However, all identifiers are context-specific and when exchanging data between systems it is important to provide additional information that makes this explicit. An entity may have any number of identifiers.
The identifier itself will be some sort of alpha-numeric string but that string only has meaning if it is contextualised. In the case of Legal Entities, the issuing of an identifier is a signal that legal entity status has been conferred on an organisation and it's important to know:
- the issuing agency;
- the date on which it was issued;
- the type of identifier issued (if the authority issues more than one type of identifier).
Person (see Core Vocabularies Specification - section 3.1 PERSON)
The Person Class is a sub class of the more general 'Agent' class that encompasses organisations, legal entities, groups etc. - any entity that is able to carry out actions. This sub class, as obvious, is referred to a human being entitled to represent the interests of an entity. It’s defined by next concepts:
Full name: The full name property contains the complete name of a person as one string. In addition to the content of given name, family name and, in some systems, patronymic name, this can carry additional parts of a person’s name such as titles, middle names or suffixes like “the third” or names which are neither a given nor a family name.
Given Name: A given name, or multiple given names, are the denominator(s) that identify an individual within a family. These are given to a person by his or her parents at birth or may be legally recognised as 'given names' through a formal process.
Family Name: A family name is usually shared by members of a family. This attribute also carries prefixes or suffixes which are part of the Family Name, e.g. “de Boer”, “van de Putte”, “von und zu Orlow”. Patronymic Name; Patronymic names are important in some countries. Iceland does not have a concept of 'family name' in the way that many other European countries do, for example. Erik Magnusson and Erika Magnusdottir are siblings, both offspring of Mangnus, irrespective of his patronymic name.
Alternative Name: Any name by which an individual is known other than their full name. Many individuals use a short form of their name, a 'middle' name as a 'first' name or a professional name. Gender: The gender of an individual should be recorded using a controlled vocabulary that is appropriate for the specific context.
Birth Name: All data associated with an individual are subject to change. Names can change for a variety of reasons, either formally or informally, and new information may come to light that means that a correction or clarification can be made to an existing record. Birth names tend to be persistent however and for this reason they are recorded by some public sector information systems. There is no granularity for birth name - the full name should be recorded in a single field.
Birth and Death Date: A date that specifies the birth date (death date) of a person.
Birth and Death Country: A person's Country of Birth and Death is defined using the Location class which is associated via the appropriate relationship.
Place of Birth and Death: The Place of Birth and Place of Death are given using the Location class which is associated via the appropriate relationship.
Citizenship, Residency and Jurisdiction: The citizenship relationship links a Person to a Jurisdiction that has conferred citizenship rights on the individual such as the right to vote, to receive certain protection from the community or the issuance of a passport. Multiple citizenships are recorded as multiple instances of the citizenship relationship. Residency typically provides an individual with a subset of the rights of a citizen. Both citizenship and residency link a Person with a Jurisdiction.
Person contact data: telephone number, e-mail address and Fax number.
Report
The report is the instance document itself, document that includes all the information required by the entity that receives the submission. It includes:
Report Data Context
Reference Reporting Period: Period to which the content of the report is referred.
Audit Status: Indicates if the date is audited or not.
<xsd:enumeration value="not audited"/> <xsd:enumeration value="audited"/>
Consolidation Status: Indicates if the data is consolidated or solo.
<xsd:enumeration value="solo head office excluding branches"/> <xsd:enumeration value="solo head office including branches"/> <xsd:enumeration value="solo branch only"/> <xsd:enumeration value="sub-consolidated"/> <xsd:enumeration value="consolidated"/>
Capital Currency: some authorities allow reportings to be multi-currency, others require all data of a report to be converted into a single currency (e.g. the capital currency of the reporting entity). This information allows to enforcement that all units used in the XBRL instances correspond to the capital currency of the reporting entity. It’s value should be a ISO 4217 code.
Report Operational Context Update Status: in case an authority only allows complete reports to be submitted, this information will always have the value “Initial”. For authorities allowing partial updates of data formerly sent, the first version should have the value “Initial” and all subsequent ones making changes to those initial data should have the value “Update”
<xsd:enumeration value="Initial"/> <xsd:enumeration value="Update"/>
Instance Creation Date Time: moment of creation of the instances
Test Flag: In order to identify if the instance document is a test or a production one.
Transfer Software Name and Version: This purely informational item can be used to indicate the communication software used to submit the container with XBRL instances. In case more than one reporting entity or technical sender has problems with e.g. a new version of a communication software, this information may help with the diagnostics and the provider can be directly contacted.
Reporting Software Name and Version: This purely informational item can be used to indicate the reporting software used to generate the XBRL instances. In case more than one reporting entity has problems with e.g. a new version of a reporting software, this information may help with the diagnostics and the providercan be directly contacted.
Remark about the Report: Other information regarding the reporting
StandardHeader: BasicHeaderOnly
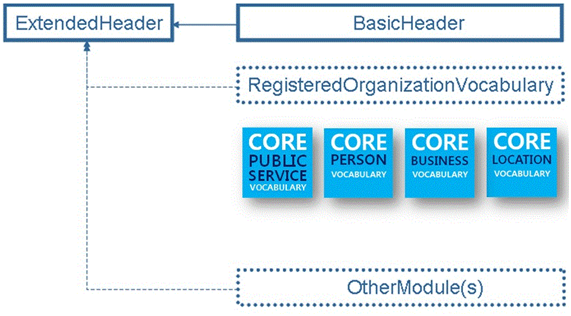
This header imports the BasicHeader « as is », makes no extensions of it and does not import the RegisteredOrganizationVocabulary as it uses none of its fields.
Namespace: http://www.eurofiling.info/eu/fr/esrs/Header/BasicHeaderOnly
XSD URL: http://www.eurofiling.info/eu/fr/esrs/Header/BasicHeaderOnly.xsd
XML sample instance URL: http://www.eurofiling.info/eu/fr/esrs/Header/BasicHeaderOnly.xml
StandardHeader: WithRegOrg
This header structure reflects the survey made within the Eurofiling BestPractices efforts which had given the results documented in http://www.wikixbrl.info/index.php?title=Best_Practices_on_Common_European_Reporting_Structures All fields related to « Transport » issues have been removed as these are out of scope of this CWA.
Namespace: http://www.eurofiling.info/eu/fr/esrs/Header/StandardHeaderWithRegOrg
XSD URL: http://www.eurofiling.info/eu/fr/esrs/Header/StandardHeaderWithRegOrg.xsd
XML sample instance URL: http://www.eurofiling.info/eu/fr/esrs/Header/StandardHeaderWithRegOrg.xml
StandardHeader: WithoutRegOrg
This header is (with regards to its function and its content) equivalent to the previous “StandardHeaderWithRegOrg”, but it does not import RegOrg and creates the missing fields as equivalent simple XML fields
Namespace: http://www.eurofiling.info/eu/fr/esrs/Header/StandardHeaderWithoutRegOrg
XSD URL: http://www.eurofiling.info/eu/fr/esrs/Header/StandardHeaderWithoutRegOrg.xsd
XML sample instance URL: http://www.eurofiling.info/eu/fr/esrs/Header/StandardHeaderWithoutRegOrg.xml
XML feedback
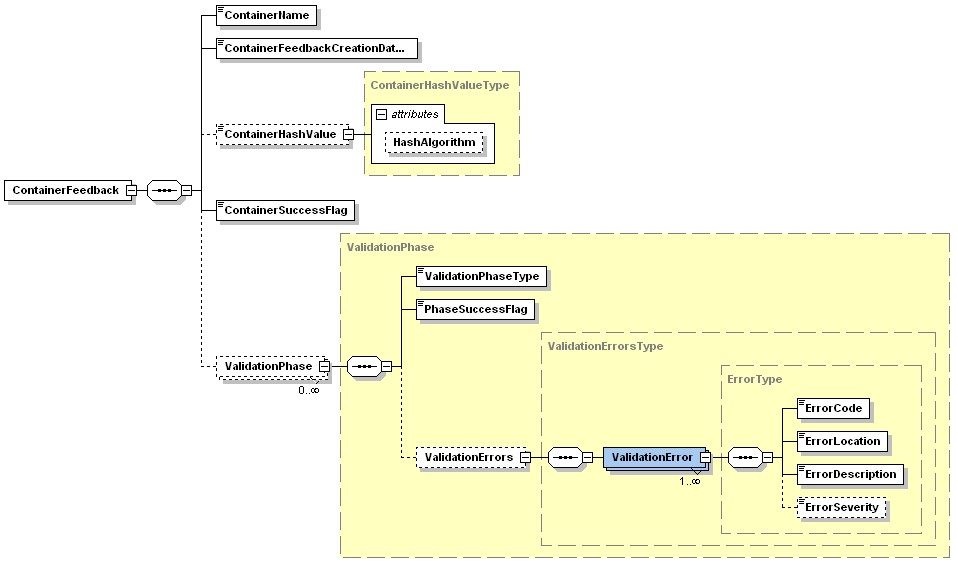
Container feedback files
A container feedback file is an XML instance of the XML schema located at: http://www.eurofiling.info/eu/fr/esrs/ContainerFeedback/ContainerFeedback.xsd
The function of the container feedback file is to confirm to the sender the success (or not) of the submission.
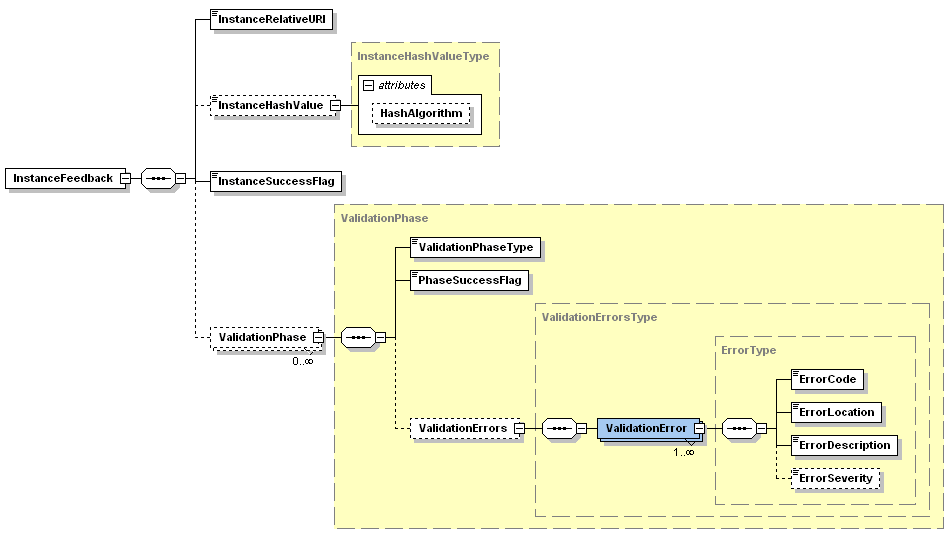
Instance feedback files
Instance feedback files are XML instances of the XML schema located at: http://www.eurofiling.info/eu/fr/esrs/InstanceFeedback/InstanceFeedback.xsd
Alternative representations of the error conditions of the data files submitted (e.g. documents with links to external systems representing the errors graphically, spread sheets with “red” cells indicating error locations, …) may be added to a response container, either as a complement or as an alternative to the XML instance feedback file. In that case the term alternative instance feedback file will be used.
XBRL Registered Organization
The Registered Organization is a vocabulary for describing organizations that have gained legal entity status through a formal registration process, typically in a national or regional register. It focuses solely on such organizations and excludes natural persons, virtual organizations and other types of legal entity or ‘agent’ that are able to act.
Registered Organization Vocabulary is a vocabulary for describing organizations that have gained legal entity status through a formal registration process, typically in a national or regional register. The Registered Organization Vocabulary includes a minimal number of classes and properties that are designed to capture the typical details recorded by business registers and thereby facilitate information exchange between them, although there is significant variation between business registers in what they record and publish.
The conceptual model of the Registered Organization Vocabulary is independent of any technology that may be used to represent it. It describes the minimal set of classes, relationships and properties necessary to describe a natural person, a business that has legal entity status, and a location. See Registered Organization Vocabulary Conceptual Model – Tables.

Registered Organization Vocabulary has been developed by and published by the European Commission ISA Programme with support from the Directorate General Internal Market and Services (DG MARKT). Contributors included representatives of Member States of the European Union, operators of national repositories, standardization bodies and independent experts whose work was published in May 2012. That document includes the history and motivation behind the development of Registered Organization Vocabulary, as well as the business need and usage scenario for it.
Registered Organization Vocabulary as a W3C standard
The Registered Organization Vocabulary (RegOrg) has now been formally published on the W3C standards track as a First Public Working Draft. It has been revised and it is now an extension of the broader Organization Ontology.

The objective of these changes is to achieve better alignment with the broader Organization Ontology (Org), which describes core ontology for organizational structures. However, the fundamentals of the Registered Organization Vocabulary remain unchanged, in particular the use of the ADMS Identifier class to capture the actual registration information.
Together, Org and RegOrg offer a powerful means to describe any organisation, its organisational units, its registered entities, its locations and its staff. The ISA programme is also currently further building on these vocabularies in the Core Public Service Vocabulary Working Group.
Initially, this vocabulary was created by a group chaired by DG MARKT of the European Commission and sponsored by the ISA Programme. This core vocabulary was designed to enable interoperability among business registers and any other ICT based solutions exchanging and processing information related to registered businesses.
Registered Organization Vocabulary as a XBRL taxonomy
It has been developed an XBRL taxonomy in order to represent the conceptual model of the Registered Organization Vocabulary (RegOrg).
The CWA2 has developed different types of headers for an XBRL instance, one of them, the extended header structure shall import the basic header structure and optionally may import other modules like the Registered Organization Vocabulary and/or other modules (to be developed in the future).
Registered Organization Vocabulary XBRL taxonomy is available at:
SCHEMA http://www.eurofiling.info/fr/cbv/tables/TablesCBV.xsd
DEFINITION LINKBASE http://www.eurofiling.info/fr/cbv/tables/TablesCBV-definition.xml
LABEL LINKBASE http://www.eurofiling.info/fr/cbv/tables/TablesCBV-label.xml
PRESENTATION LINKBASE http://www.eurofiling.info/fr/cbv/tables/TablesCBV-presentation.xml
XBRL test instances are available at:
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT1.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT2.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT3.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT4.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT5.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT6.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT7.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT8.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT9.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceT10.xbrl
http://www.eurofiling.info/fr/cbv/exampleInstances/instanceAllTables.xbrl
and the equivalent Excel document at:
http://www.eurofiling.info/fr/cbv/exampleInstances/ExamplesConceptualModel-TablesCBV-20130213.xlsx
Bibliography
[1] xxx [2] xxx

